


AI agents struggle with tasks that require interacting with the live web — fetching a competitor’s pricing page, extracting structured data from a JavaScript-heavy dashboard, or automating a multi-step workflow on a real site. The tooling has been fragmented, requiring teams to stitch together separate providers for search, browser automation, and content retrieval.
TinyFish, a Palo Alto-based startup that previously shipped a standalone web agent, is launching what it describes as the complete infrastructure platform for AI agents operating on the live web. This launch introduces four products unified under a single API key and a single credit system: Web Agent, Web Search, Web Browser, and Web Fetch.
What TinyFish is Shipping
Here is what each product does:
Web Agent — Executes autonomous multi-step workflows on real websites. The agent navigates sites, fills forms, clicks through flows, and returns structured results without requiring manually scripted steps.
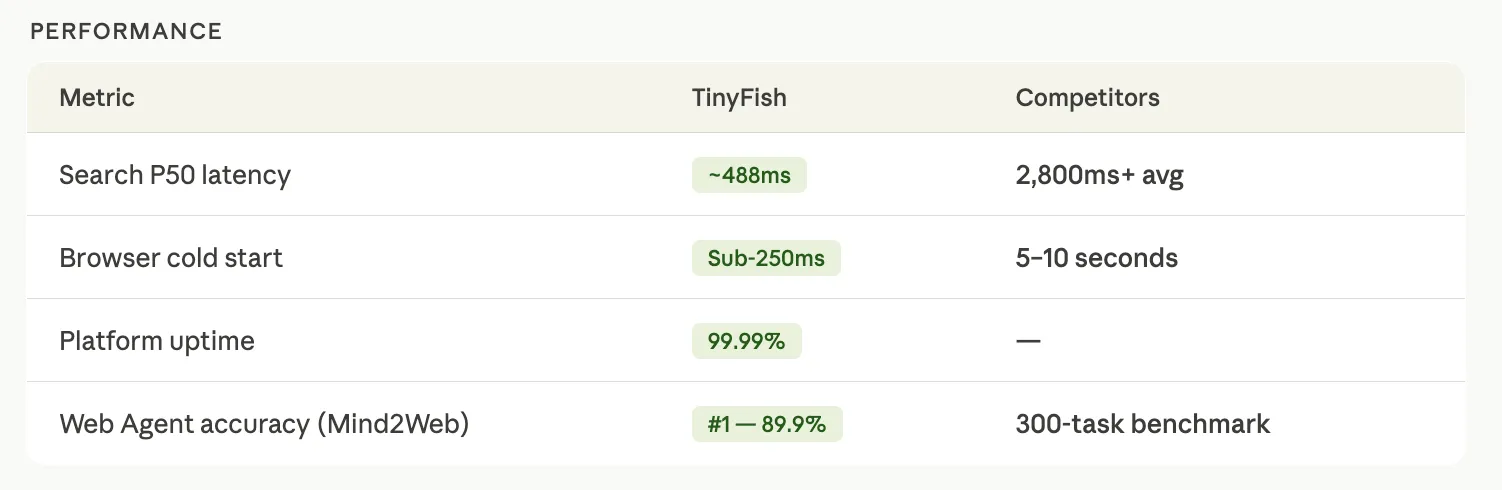
Web Search — Returns structured search results as clean JSON using a custom Chromium engine, with a P50 latency of approximately 488ms. Competitors in this space average over 2,800ms for the same operation.
Web Browser — Provides managed stealth Chrome sessions via the Chrome DevTools Protocol (CDP), with a sub-250ms cold start. Competitors typically take 5–10 seconds. The browser includes 28 anti-bot mechanisms built at the C++ level — not via JavaScript injection, which is the more common and more detectable approach.
Web Fetch — Converts any URL into clean Markdown, HTML, or JSON with full browser rendering. Unlike the native fetch tools built into many AI coding agents, TinyFish Fetch strips irrelevant markup — CSS, scripts, navigation, ads, footers — and returns only the content the agent needs.
The Token Problem in Agent Pipelines
One of the consistent performance problems in agent pipelines is context window pollution. When an AI agent uses a standard web fetch tool, it typically pulls the entire page — including thousands of tokens of navigation elements, ad code, and boilerplate markup — and puts all of it into the model’s context window before reaching the actual content.
TinyFish Fetch addresses this by rendering the page in a full browser and returning only the clean text content as Markdown or JSON. The company’s benchmarks show CLI-based operations using approximately 100 tokens per operation versus roughly 1,500 tokens when routing the same workflow over MCP — an 87% reduction per operation.
Beyond token count, there is an architectural difference worth understanding: MCP operations return output directly into the agent’s context window. The TinyFish CLI writes output to the filesystem, and the agent reads only what it needs. This keeps the context window clean across multi-step tasks and enables composability through native Unix pipes and redirects — something that is not possible with sequential MCP round-trips.
On complex multi-step tasks, TinyFish reports 2× higher task completion rates using CLI + Skills compared to MCP-based execution.
The CLI and Agent Skill System
TinyFish is shipping two developer-facing components alongside the API endpoints.
The CLI installs with a single command:
This gives terminal access to all four endpoints — Search, Fetch, Browser, and Agent — directly from the command line.
The Agent Skill is a markdown instruction file (SKILL.md) that teaches AI coding agents — including Claude Code, Cursor, Codex, OpenClaw, and OpenCode — how to use the CLI. Install it with:
Once installed, the agent learns when and how to call each TinyFish endpoint without manual SDK integration or configuration. A developer can ask their coding agent to “get competitor pricing from these five sites,” and the agent autonomously recognizes the TinyFish skill, calls the appropriate CLI commands, and writes structured output to the filesystem — without the developer writing integration code.
The company also notes that MCP remains supported. The positioning is that MCP is suited for discovery, while CLI + Skills is the recommended path for heavy-duty, multi-step web execution.
Why a Unified Stack?
TinyFish built Search, Fetch, Browser, and Agent entirely in-house. This is a meaningful distinction from some competitors. For example, Browserbase uses Exa to power its Search endpoint, meaning that layer is not proprietary. Firecrawl offers search, crawl, and an agent endpoint, but the agent endpoint has reliability issues on many tasks.
The infrastructure argument is not only about avoiding vendor dependencies. When every layer of the stack is owned by the same team, the system can optimize for a single outcome: whether the task completed. When TinyFish’s agent succeeds or fails using its own search and fetch, the company gets end-to-end signal at every step — what was searched, what was fetched, and exactly where failures occurred. Companies whose search or fetch layer runs on a third-party API do not have access to this signal.
There is also a practical cost that teams integrating multiple providers encounter. Search finds a page the fetch layer cannot render. Fetch returns content the agent cannot parse. Browser sessions drop context between steps. The result is custom glue code, retry logic, fallback handlers, and validation layers — engineering work that adds up. A unified stack removes the component boundaries where these failures occur.
The platform also maintains session consistency across steps: same IP, same fingerprint, same cookies throughout a workflow. Separate tools operating independently appear to a target site as multiple unrelated clients, which increases the likelihood of detection and session failure.
Key Metrics


Key Takeaways
TinyFish moves from a single web agent to a four-product platform — Web Agent, Web Search, Web Browser, and Web Fetch — all accessible under one API key and one credit system, eliminating the need to manage multiple providers.
The CLI + Agent Skill combination lets AI coding agents use the live web autonomously — install once and agents like Claude Code, Cursor, and Codex automatically know when and how to call each TinyFish endpoint, with no manual integration code.
CLI-based operations produce 87% fewer tokens per task than MCP, and write output directly to the filesystem instead of dumping it into the agent’s context window — keeping context clean across multi-step workflows.
Every layer of the stack — Search, Fetch, Browser, and Agent — is built in-house, giving end-to-end signals when a task succeeds or fails, a data feedback loop that cannot be replicated by assembling third-party APIs.
TinyFish maintains a single session identity across an entire workflow — same IP, fingerprint, and cookies — whereas separate tools appear to target sites as multiple unrelated clients, increasing detection risk and failure rates.
Getting Started
TinyFish offers 500 free steps with no credit card required at tinyfish.ai. The open-source cookbook and Skill files are available at github.com/tinyfish-io/tinyfish-cookbook, and CLI documentation is at docs.tinyfish.ai/cli.
Note: Thanks for the leadership at Tinyfish for supporting and providing details for this article.