


How far can we push large language model speed by reusing “free” GPU compute, without giving up autoregressive level output quality? NVIDIA researchers propose TiDAR, a sequence level hybrid language model that drafts tokens with diffusion and samples them autoregressively in a single forward pass. The main goal of this research is to reach autoregressive quality while significantly increasing throughput by exploiting free token slots on modern GPUs.
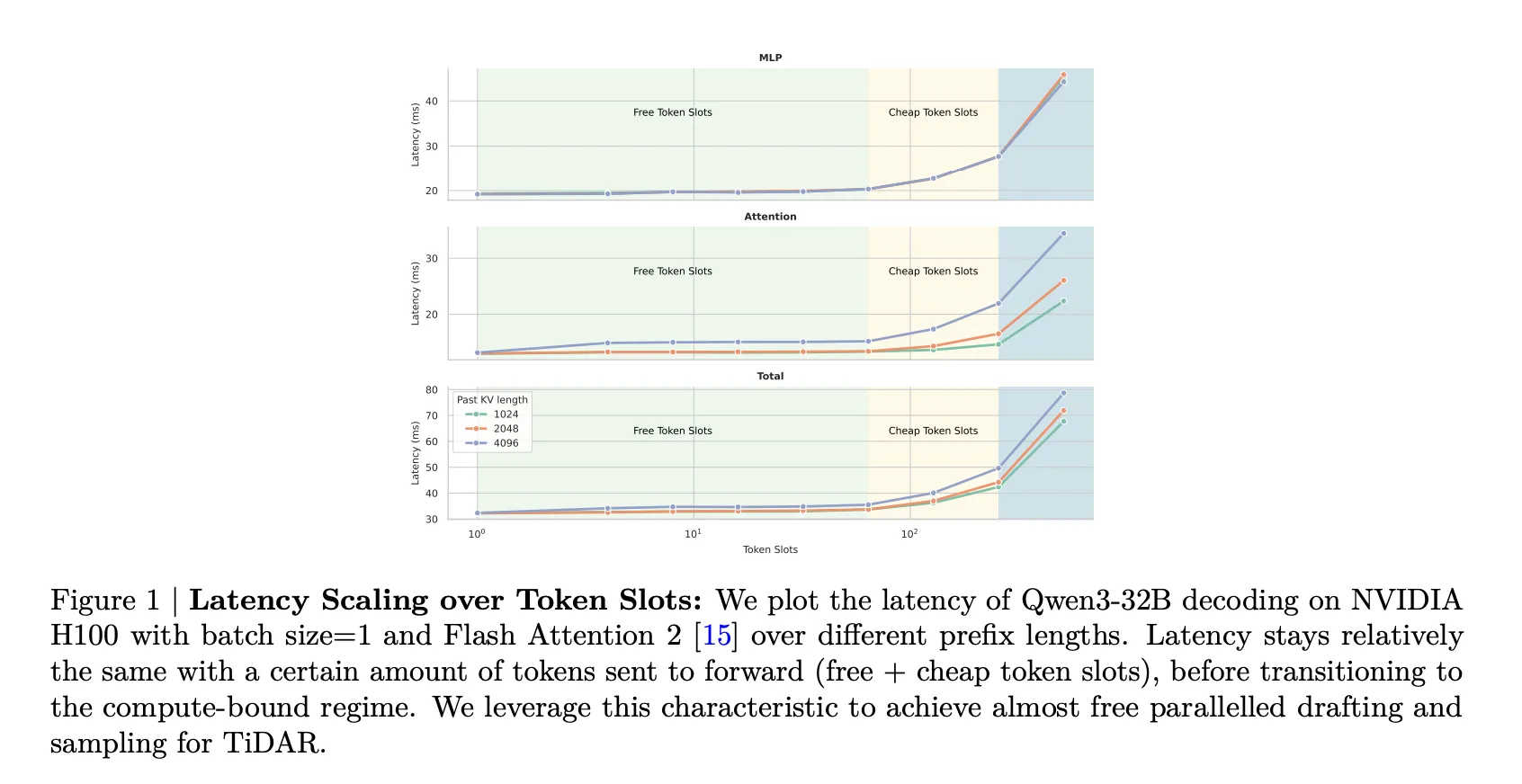
Systems motivation, free token slots and the quality problem
Autoregressive transformers decode one token per step. At realistic batch sizes, decoding is usually memory bound, because latency is dominated by loading weights and KV cache, not by floating point operations. Increasing the number of tokens in the input sequence within the memory bound region does not change latency much, since the same parameters and cache are reused.
Masked diffusion language models already exploit this. Given a prefix, they can append multiple masked positions and predict several tokens in parallel in one denoising step. The research team calls these additional positions free token slots, because profiling shows that sending more tokens in this regime barely changes the forward time.
However, diffusion LLMs like Dream and Llada still underperform strong autoregressive baselines on quality. When these models decode multiple tokens in the same step, they sample each token independently from a marginal distribution, given a noised context. This intra step token independence hurts sequence level coherence and factual correctness, and the best quality is usually obtained when decoding only 1 token per step. In practice, this removes much of the theoretical speed advantage of diffusion decoding.
TiDAR is designed to preserve the compute efficiency of diffusion while recovering autoregressive quality, using a single backbone and standard transformer infrastructure.
Architecture, dual mode backbone and attention masks
At a high level, TiDAR partitions the sequence at each generation step into three sections:
A prefix of accepted tokens.
Tokens drafted in the previous step.
Mask tokens that will hold pre drafted candidates for the next step.
The model applies a structured attention mask across this sequence. Prefix tokens attend causally, which supports chain factorized next token prediction, as in a standard autoregressive transformer. Tokens in the drafting region and mask region attend bidirectionally within a block, which enables diffusion style marginal predictions over many positions in parallel. This layout is a modification of the Block Diffusion mask, where only the decoding block is bidirectional and the rest of the sequence remains causal.

To enable both modes in the same backbone, TiDAR doubles the sequence length at training time. The original input occupies the causal section, and a corrupted copy occupies the diffusion section. In the causal section, labels are shifted by 1 token to match the next token prediction objective. In the diffusion section, labels are aligned with the input positions.
Crucially, TiDAR uses a full mask strategy. All tokens in the diffusion section are replaced by a special mask token, rather than sampling a sparse corruption pattern. This makes the diffusion loss dense, keeps the number of loss terms in diffusion and autoregressive parts equal to the sequence length, and simplifies balancing the two losses with a single weighting factor. The research team set this weighting factor to 1 in most experiments.

Self speculative generation in one forward pass
Generation is formulated as a self speculative process that runs in a single network function evaluation per step.
Step 1, given the prompt, TiDAR encodes the prefix causally and performs one step diffusion over the mask positions, producing a block of drafted tokens.
Step 2 and later steps, each forward pass performs two operations at once
Verification of drafted tokens using autoregressive logits over the extended prefix with a rejection sampling rule, similar in spirit to speculative decoding.
Pre drafting of the next block using diffusion, conditioned on all possible acceptance outcomes of the current step.
Accepted tokens are added to the prefix, and their KV cache entries are retained. Rejected tokens are discarded, and their cache entries are evicted. The drafting and verification share the same backbone and attention mask, so diffusion computation uses the free token slots in the same forward pass.
The model supports two sampling modes, trusting autoregressive predictions or trusting diffusion predictions, which control how strongly the final sample follows each head. Experiments show that for the 8B model, trusting diffusion predictions is often beneficial, especially on math benchmarks, while retaining autoregressive quality through rejection sampling.
On the systems side, the attention layout and number of tokens per step are fixed. TiDAR pre initialises a block attention mask and reuses slices of this mask across decoding steps using Flex Attention. The architecture supports exact KV cache, like Block Diffusion. The implementation never recomputes KV entries for accepted tokens and introduces no extra inference time hyperparameters.
Training recipe and model sizes
TiDAR is instantiated by continual pretraining from Qwen2.5 1.5B and Qwen3 4B and 8B base models. The 1.5B variant is trained on 50B tokens with block sizes 4, 8 and 16. The 8B variant is trained on 150B tokens with block size 16. Both use maximum sequence length 4096, cosine learning rate schedule, distributed Adam, BF16, and a modified Megatron LM framework with Torchtitan on NVIDIA H100 GPUs.
Evaluation covers coding tasks HumanEval, HumanEval Plus, MBPP, MBPP Plus, math tasks GSM8K and Minerva Math, factual and commonsense tasks MMLU, ARC, Hellaswag, PIQA, and Winogrande, all implemented via lm_eval_harness.
Quality and throughput results
On generative coding and math tasks, TiDAR 1.5B is highly competitive with its autoregressive counterpart, while generating an average 7.45 tokens per model forward. TiDAR 8B incurs only minimal quality loss relative to Qwen3 8B while increasing generation efficiency to 8.25 tokens per forward pass.
On knowledge and reasoning benchmarks evaluated by likelihood, TiDAR 1.5B and 8B match the overall behaviour of comparable autoregressive models, because likelihood is computed with a pure causal mask. Diffusion baselines such as Dream, Llada and Block Diffusion require Monte Carlo based likelihood estimators, which are more expensive and less directly comparable.
In wall clock benchmarks on a single H100 GPU with batch size 1, TiDAR 1.5B reaches an average 4.71 times speedup in decoding throughput relative to Qwen2.5 1.5B, measured in tokens per second. TiDAR 8B reaches 5.91 times speedup over Qwen3 8B, again while maintaining comparable quality.
Compared with diffusion LLMs, TiDAR consistently outperforms Dream and Llada in both efficiency and accuracy, under the constraint that diffusion models decode 1 token per forward pass for best quality. Compared with speculative frameworks such as EAGLE-3 and training matched Block Diffusion, TiDAR dominates the efficiency quality frontier by converting more tokens per forward into real tokens per second, thanks to the unified backbone and parallel drafting and verification.
Key Takeaways
TiDAR is a sequence level hybrid architecture that drafts tokens with diffusion and samples them autoregressively in a single model pass, using a structured attention mask that mixes causal and bidirectional regions.
The design explicitly exploits free token slots on GPUs, it appends diffusion drafted and masked tokens to the prefix so that many positions are processed in one forward pass with almost unchanged latency, improving compute density during decoding.
TiDAR implements self speculative generation, the same backbone both drafts candidate tokens with one step diffusion and verifies them with autoregressive logits and rejection sampling, which avoids the separate draft model overhead of classic speculative decoding.
Continual pretraining from Qwen2.5 1.5B and Qwen3 4B and 8B with a full mask diffusion objective allows TiDAR to reach autoregressive level quality on coding, math and knowledge benchmarks, while keeping exact likelihood evaluation through pure causal masking when needed.
In single GPU, batch size 1 settings, TiDAR delivers about 4.71 times more tokens per second for the 1.5B model and 5.91 times for the 8B model than their autoregressive baselines, while outperforming diffusion LLMs like Dream and Llada and closing the quality gap with strong autoregressive models.
Comparison
TiDAR is a useful step toward bridging autoregressive decoding and diffusion language models using one unified backbone. By exploiting free token slots and self speculative generation, it raises tokens per network function evaluation without degrading GSM8K, HumanEval, or MMLU performance relative to Qwen baselines. The full mask diffusion objective and exact KV cache support also make it practical for production style serving on H100 GPUs. Overall, TiDAR shows that diffusion drafting and autoregressive verification can coexist in a single efficient LLM architecture.
Check out the PAPER. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.