


Earth observation (EO) constellations capture huge volumes of high-resolution imagery every day, but most of it never reaches the ground in time for model training. Downlink bandwidth is the main bottleneck. Images can sit on orbit for days while ground models train on partial and delayed data.
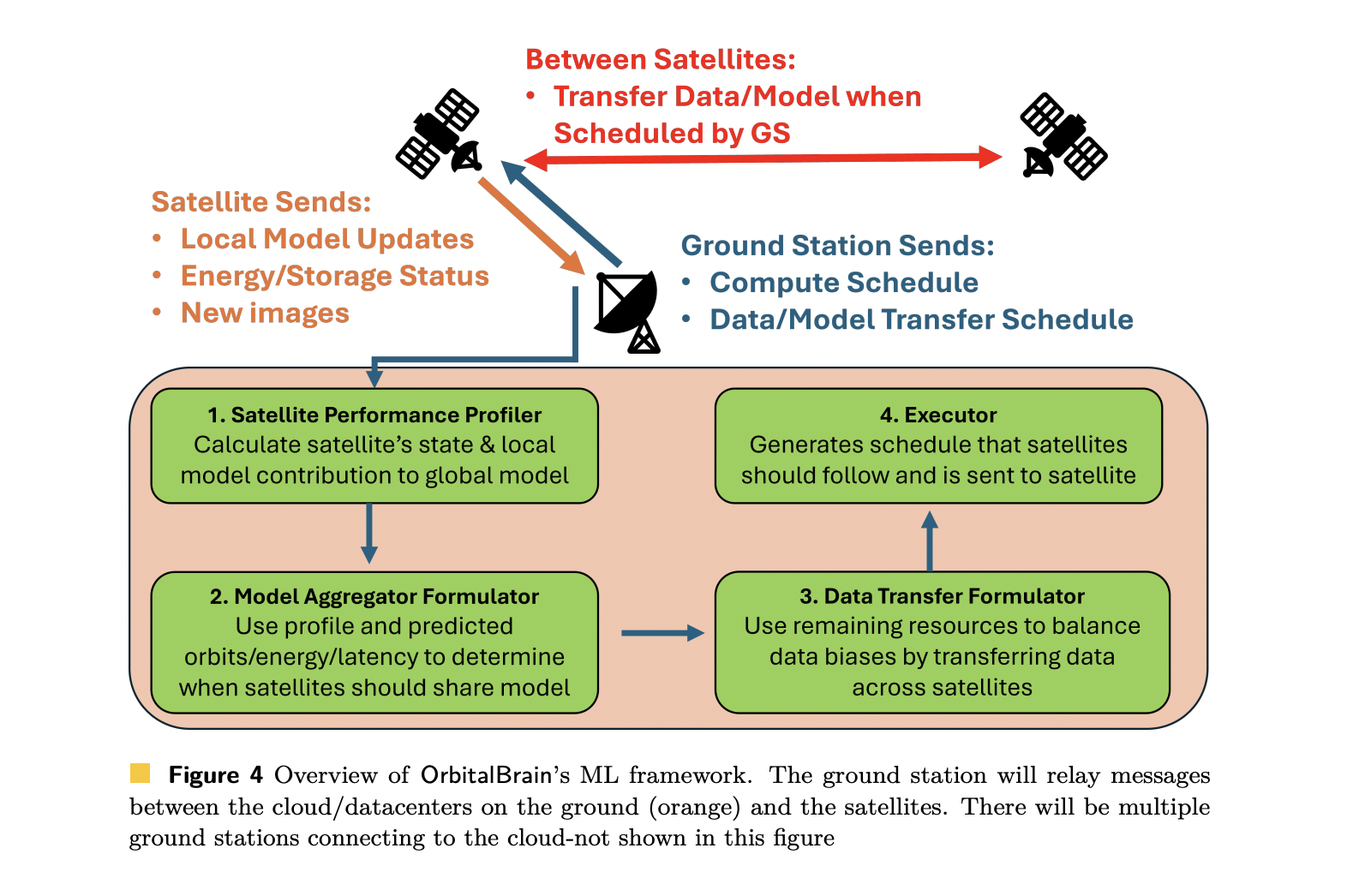
Microsoft Researchers introduced ‘OrbitalBrain’ framework as a different approach. Instead of using satellites only as sensors that relay data to Earth, it turns a nanosatellite constellation into a distributed training system. Models are trained, aggregated, and updated directly in space, using onboard compute, inter-satellite links, and predictive scheduling of power and bandwidth.
The BentPipe Bottleneck
Most commercial constellations use the BentPipe model. Satellites collect images, store them locally, and dump them to ground stations whenever they pass overhead.
The research team evaluates a Planet-like constellation with 207 satellites and 12 ground stations. At maximum imaging rate, the system captures 363,563 images per day. With 300 MB per image and realistic downlink constraints, only 42,384 images can be transmitted in that period, around 11.7% of what was captured. Even if images are compressed to 100 MB, only 111,737 images, about 30.7%, reach the ground within 24 hours.
Limited onboard storage adds another constraint. Old images must be deleted to make room for new ones, which means many potentially useful samples are never available for ground-based training.
Why Conventional Federated Learning is not Enough
Federated learning (FL) seems like an obvious fit for satellites. Each satellite could train locally and send model updates to a ground server for aggregation. The research team evaluate several FL baselines adapted to this setting:
AsyncFL
SyncFL
FedBuff
FedSpace
However, these methods assume more stable communication and more flexible power than satellites can provide. When the research team simulate realistic orbital dynamics, intermittent ground contact, limited power, and non-i.i.d. data across satellites, these baselines show unstable convergence and large accuracy drops, in the range of 10%–40% compared to idealized conditions.
The time-to-accuracy curves flatten and oscillate, especially when satellites are isolated from ground stations for long periods. Many local updates become stale before they can be aggregated.
OrbitalBrain: Constellation-Centric Training in Space
OrbitalBrain starts from 3 observations:
Constellations are usually operated by a single commercial entity, so raw data can be shared across satellites.
Orbits, ground station visibility, and solar power are predictable from orbital elements and power models.
Inter-satellite links (ISLs) and onboard accelerators are now practical on nano-satellites.
The framework exposes 3 actions for each satellite in a scheduling window:
Local Compute (LC): train the local model on stored images.
Model Aggregation (MA): exchange and aggregate model parameters over ISLs.
Data Transfer (DT): exchange raw images between satellites to reduce data skew.
A controller running in the cloud, reachable via ground stations, computes a predictive schedule for each satellite. The schedule decides which action to prioritize in each future window, based on forecasts of energy, storage, orbital visibility, and link opportunities.
Core Components: Profiler, MA, DT, Executor
Guided performance profiler
Model aggregation over ISLs
Data transferrer for label rebalancing
Executor
Experimental setup
OrbitalBrain is implemented in Python on top of the CosmicBeats orbital simulator and the FLUTE federated learning framework. Onboard compute is modeled as an NVIDIA-Jetson-Orin-Nano-4GB GPU, with power and communication parameters calibrated from public satellite and radio specifications.
The research team simulate 24-hour traces for 2 real constellations:
Planet: 207 satellites with 12 ground stations.
Spire: 117 satellites.
They evaluate 2 EO classification tasks:
fMoW: around 360k RGB images, 62 classes, DenseNet-161 with the last 5 layers trainable.
So2Sat: around 400k multispectral images, 17 classes, ResNet-50 with the last 5 layers trainable.
Results: faster time-to-accuracy and higher accuracy
OrbitalBrain is compared with BentPipe, AsyncFL, SyncFL, FedBuff, and FedSpace under full physical constraints.
For fMoW, after 24 hours:
Planet: OrbitalBrain reaches 52.8% top-1 accuracy.
Spire: OrbitalBrain reaches 59.2% top-1 accuracy.
For So2Sat:
Planet: 47.9% top-1 accuracy.
Spire: 47.1% top-1 accuracy.
These results improve over the best baseline by 5.5%–49.5%, depending on dataset and constellation.
In terms of time-to-accuracy, OrbitalBrain achieves 1.52×–12.4× speedup compared to state-of-the-art ground-based or federated learning approaches. This comes from using satellites that cannot currently reach a ground station by aggregating over ISLs and from rebalancing data distributions via DT.
Ablation studies show that disabling MA or DT significantly degrades both convergence speed and final accuracy. Additional experiments indicate that OrbitalBrain remains robust when cloud cover hides part of the imagery, when only a subset of satellites participate, and when image sizes and resolutions vary.
Implications for satellite AI workloads
OrbitalBrain demonstrates that model training can move into space and that satellite constellations can act as distributed ML systems, not just data sources. By coordinating local training, model aggregation, and data transfer under strict bandwidth, power, and storage constraints, the framework enables fresher models for tasks like forest fire detection, flood monitoring, and climate analytics, without waiting days for data to reach terrestrial data centers.
Key Takeaways
BentPipe downlink is the core bottleneck: Planet-like EO constellations can only downlink about 11.7% of captured 300 MB images per day, and about 30.7% even with 100 MB compression, which severely limits ground-based model training.
Standard federated learning fails under real satellite constraints: AsyncFL, SyncFL, FedBuff, and FedSpace degrade by 10%–40% in accuracy when realistic orbital dynamics, intermittent links, power limits, and non-i.i.d. data are applied, leading to unstable convergence.
OrbitalBrain co-schedules compute, aggregation, and data transfer in orbit: A cloud controller uses forecasts of orbit, power, storage, and link opportunities to select Local Compute, Model Aggregation via ISLs, or Data Transfer per satellite, maximizing a utility function per action.
Label rebalancing and model staleness are handled explicitly: A guided profiler tracks model staleness and loss to define compute utility, while the data transferrer uses Jensen–Shannon divergence on label histograms to drive raw-image exchanges that reduce non-i.i.d. effects.
OrbitalBrain delivers higher accuracy and up to 12.4× faster time-to-accuracy: In simulations on Planet and Spire constellations with fMoW and So2Sat, OrbitalBrain improves final accuracy by 5.5%–49.5% over BentPipe and FL baselines and achieves 1.52×–12.4× speedups in time-to-accuracy.
Check out the Paper. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
