


How do you design a single model that can listen, see, read and respond in real time across text, image, video and audio without losing the efficiency? Meituan’s LongCat team has released LongCat Flash Omni, an open source omni modal model with 560 billion parameters and about 27 billion active per token, built on the shortcut connected Mixture of Experts design that LongCat Flash introduced. The model extends the text backbone to vision, video and audio, and it keeps a 128K context so it can run long conversations and document level understanding in one stack.
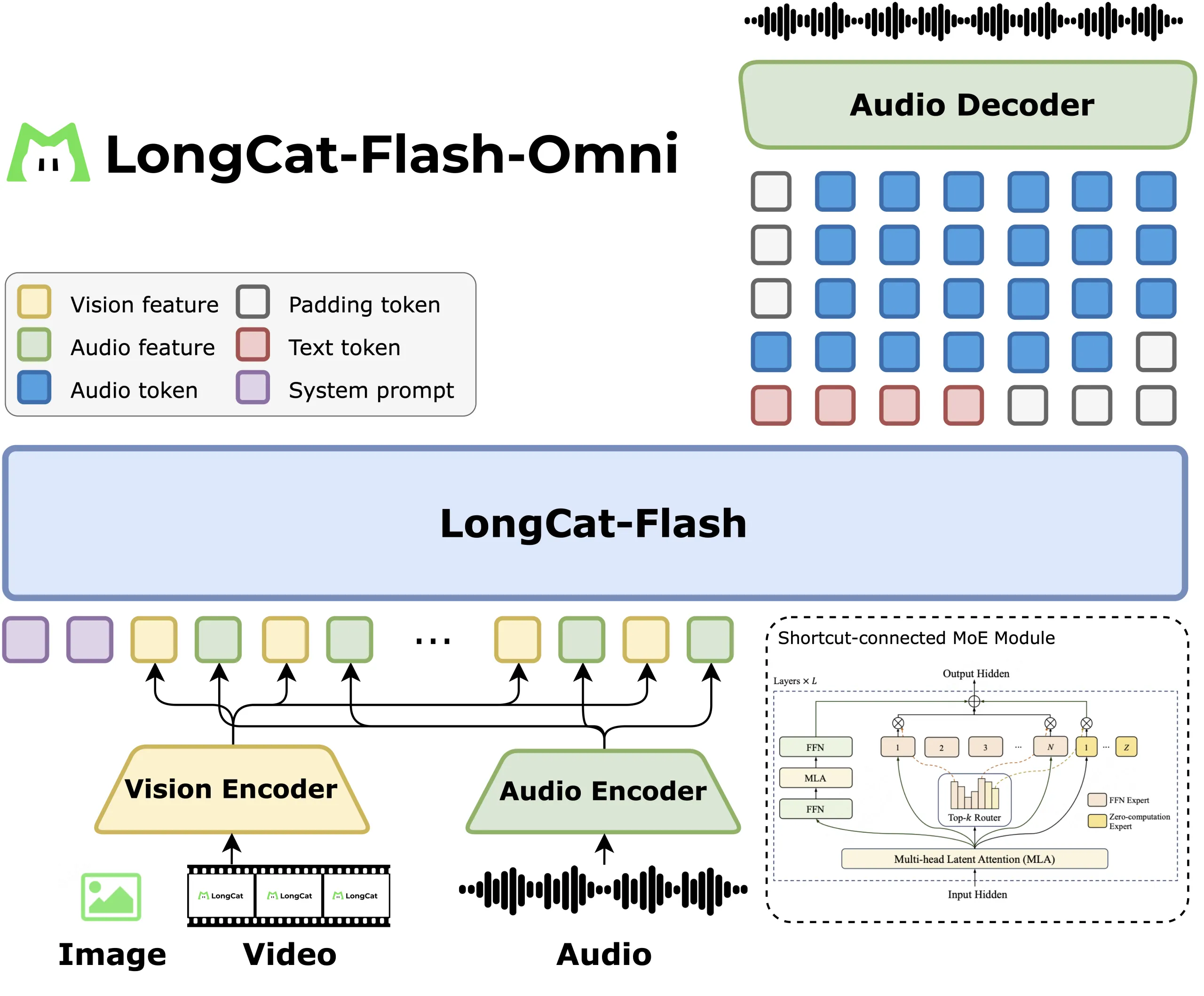
Architecture and Modal Attachments
LongCat Flash Omni keeps the language model unchanged, then adds perception modules. A LongCat ViT encoder processes both images and video frames so there is no separate video tower. An audio encoder together with the LongCat Audio Codec turns speech into discrete tokens, then the decoder can output speech from the same LLM stream, which enables real time audio visual interaction.
Streaming and Feature Interleaving
The research team describes chunk wise audio visual feature interleaving, where audio features, video features and timestamps are packed into 1 second segments. Video is sampled at 2 frames per second by default, then the rate is adjusted according to video length, the report does not tie the sampling rule to user or model speaking phases, so the correct description is duration conditioned sampling. This keeps latency low and still provides spatial context for GUI, OCR and video QA tasks.
Curriculum from Text to Omni
Training follows a staged curriculum. The research team first trains the LongCat Flash text backbone, which activates 18.6B to 31.3B parameters per token, average 27B, then applies text speech continued pretraining, then multimodal continued pretraining with image and video, then context extension to 128K, then audio encoder alignment.
Systems Design, Modality Decoupled Parallelism
Because the encoders and the LLM have different compute patterns, Meituan uses modality decoupled parallelism. Vision and audio encoders run with hybrid sharding and activation recomputation, the LLM runs with pipeline, context and expert parallelism, and a ModalityBridge aligns embeddings and gradients. The research team reports that multimodal supervised fine tuning keeps more than 90 percent of the throughput of text only training, which is the main systems result in this release.
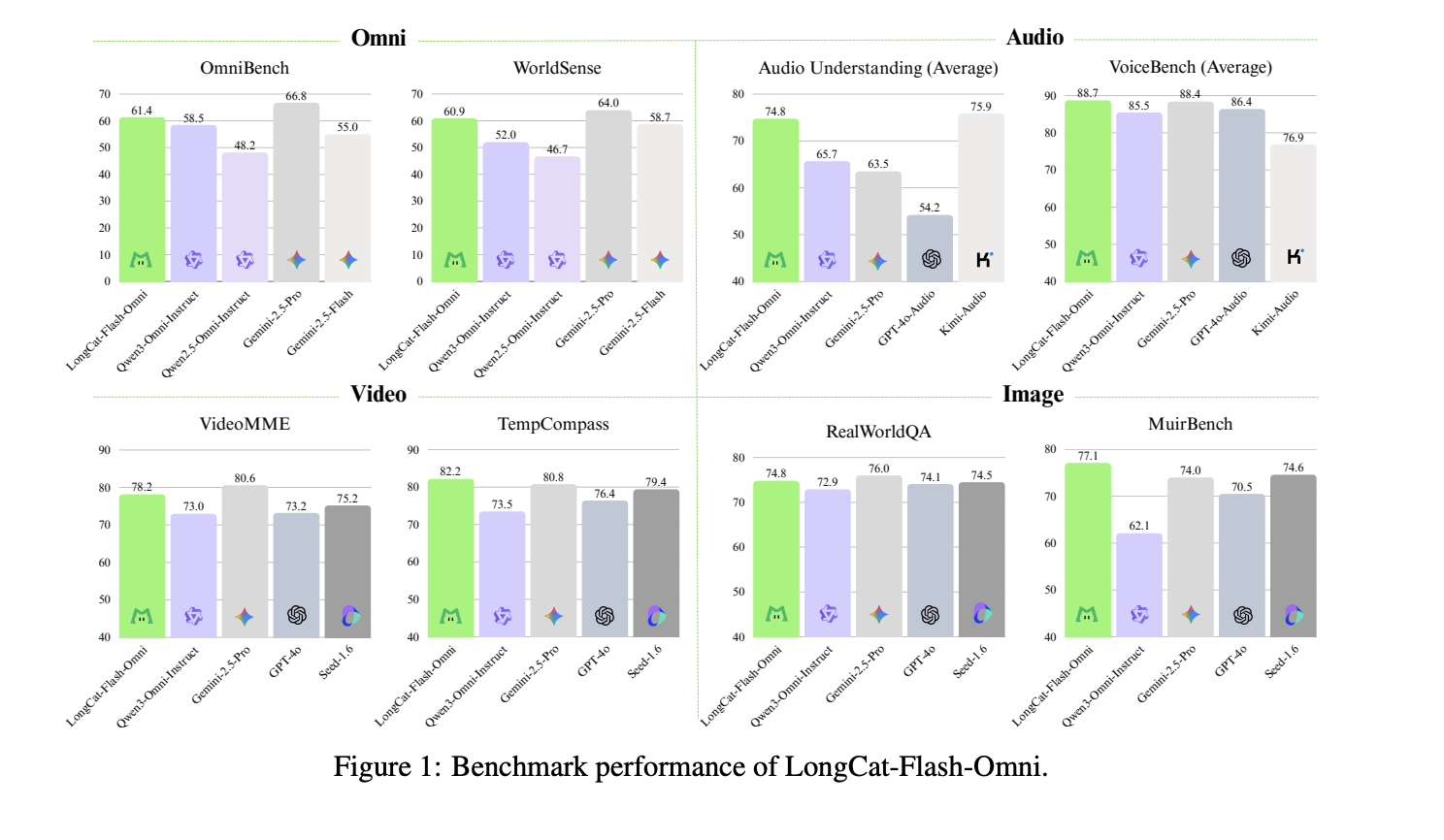
Benchmarks and Positioning
LongCat Flash Omni reaches 61.4 on OmniBench, this is higher than Qwen 3 Omni Instruct at 58.5 and Qwen 2.5 Omni at 55.0, but lower than Gemini 2.5 Pro at 66.8. On VideoMME it scores 78.2, which is close to GPT 4o and Gemini 2.5 Flash, and on VoiceBench it reaches 88.7, slightly higher than GPT 4o Audio in the same table.
Key Takeaways
LongCat Flash Omni is an open source omni modal model built on Meituan’s 560B MoE backbone, it activates about 27B parameters per token through shortcut connected MoE with zero computation experts, so it keeps large capacity but inference friendly compute.
The model attaches unified vision video encoding and a streaming audio path to the existing LongCat Flash LLM, using 2 fps default video sampling with duration conditioned adjustment, and packs audio visual features into 1 second chunks for synchronized decoding, which is what enables real time any to any interaction.
LongCat Flash Omni scores 61.4 on OmniBench, above Qwen 3 Omni Instruct at 58.5, but below Gemini 2.5 Pro at 66.8.
Meituan uses modality decoupled parallelism, vision and audio encoders run with hybrid sharding, the LLM runs with pipeline, context and expert parallelism, and report more than 90 percent of text only throughput for multimodal SFT, which is the main systems contribution of the release.
This release shows that Meituan is trying to make omni modal interaction practical, not experimental. It keeps the 560B Shortcut connected Mixture of Experts with 27B activated, so the language backbone stays compatible with earlier LongCat releases. It adds streaming audio visual perception with 2 fps default video sampling and duration conditioned adjustment, so latency remains low without losing spatial grounding. It reports over 90 percent text only throughput in multimodal supervised fine tuning through modality decoupled parallelism.
Check out the Paper, Model Weights and GitHub Repo. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.

Michal Sutter is a data science professional with a Master of Science in Data Science from the University of Padova. With a solid foundation in statistical analysis, machine learning, and data engineering, Michal excels at transforming complex datasets into actionable insights.