


Anthropic has launched Claude Opus 4.6, its most capable model to date, focused on long-context reasoning, agentic coding, and high-value knowledge work. The model builds on Claude Opus 4.5 and is now available on claude.ai, the Claude API, and major cloud providers under the ID claude-opus-4-6.
Model focus: agentic work, not single answers
Opus 4.6 is designed for multi-step tasks where the model must plan, act, and revise over time. As per the Anthropic team, they use it in Claude Code and report that it focuses more on the hardest parts of a task, handles ambiguous problems with better judgment, and stays productive over longer sessions.
The model tends to think more deeply and revisit its reasoning before answering. This improves performance on difficult problems but can increase cost and latency on simple ones. Anthropic exposes a /effort parameter with 4 levels — low, medium, high (default), and max — so developers can explicitly trade off reasoning depth against speed and cost per endpoint or use case.
Beyond coding, Opus 4.6 targets practical knowledge-work tasks:
running financial analyses
doing research with retrieval and browsing
using and creating documents, spreadsheets, and presentations
Inside Cowork, Anthropic’s autonomous work surface, the model can run multi-step workflows that span these artifacts without continuous human prompting.
Long-context capabilities and developer controls
Opus 4.6 is the first Opus-class model with a 1M token context window in beta. For prompts above 200k tokens in this 1M-context mode, pricing rises to $10 per 1M input tokens and $37.50 per 1M output tokens. The model supports up to 128k output tokens, which is enough for very long reports, code reviews, or structured multi-file edits in one response.
To make long-running agents manageable, Anthropic ships several platform features around Opus 4.6:
Adaptive thinking: the model can decide when to use extended thinking based on task difficulty and context, instead of always running at maximum reasoning depth.
Effort controls: 4 discrete effort levels (low, medium, high, max) expose a clean control surface for latency vs reasoning quality.
Context compaction (beta): the platform automatically summarizes and replaces older parts of the conversation as a configurable context threshold is approached, reducing the need for custom truncation logic.
US-only inference: workloads that must stay in US regions can run at 1.1× token pricing.
These controls target a common real-world pattern: agentic workflows that accumulate hundreds of thousands of tokens while interacting with tools, documents, and code over many steps.
Product integrations: Claude Code, Excel, and PowerPoint
Anthropic has upgraded its product stack so that Opus 4.6 can drive more realistic workflows for engineers and analysts.
In Claude Code, a new ‘agent teams’ mode (research preview) lets users create multiple agents that work in parallel and coordinate autonomously. This is aimed at read-heavy tasks such as codebase reviews. Each sub-agent can be taken over interactively, including via tmux, which fits terminal-centric engineering workflows.
Claude in Excel now plans before acting, can ingest unstructured data and infer structure, and can apply multi-step transformations in a single pass. When paired with Claude in PowerPoint, users can move from raw data in Excel to structured, on-brand slide decks. The model reads layouts, fonts, and slide masters so generated decks stay aligned with existing templates. Claude in PowerPoint is currently in research preview for Max, Team, and Enterprise plans.
Benchmark profile: coding, search, long-context retrieval
Anthropic team positions Opus 4.6 as state of the art on several external benchmarks that matter for coding agents, search agents, and professional decision support.
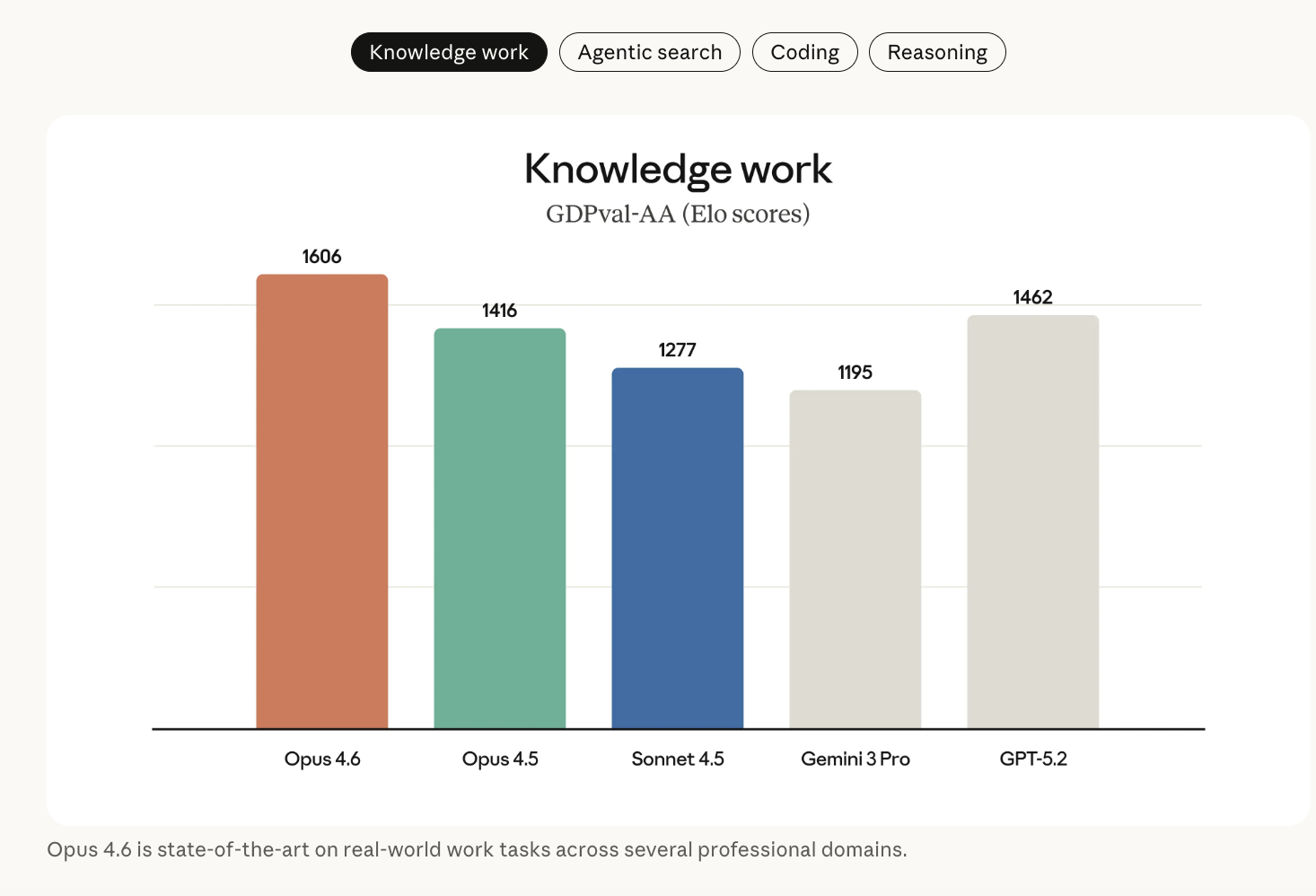
Key results include:
GDPval-AA (economically valuable knowledge work in finance, legal, and related domains): Opus 4.6 outperforms OpenAI’s GPT-5.2 by around 144 Elo points and Claude Opus 4.5 by 190 points. This implies that, in head-to-head comparisons, Opus 4.6 beats GPT-5.2 on this evaluation about 70% of the time.
Terminal-Bench 2.0: Opus 4.6 achieves the highest reported score on this agentic coding and system task benchmark.
Humanity’s Last Exam: on this multidisciplinary reasoning test with tools (web search, code execution, and others), Opus 4.6 leads other frontier models, including GPT-5.2 and Gemini 3 Pro configurations, under the documented harness.
BrowseComp: Opus 4.6 performs better than any other model on this agentic search benchmark. When Claude models are combined with a multi-agent harness, scores increase to 86.8%.
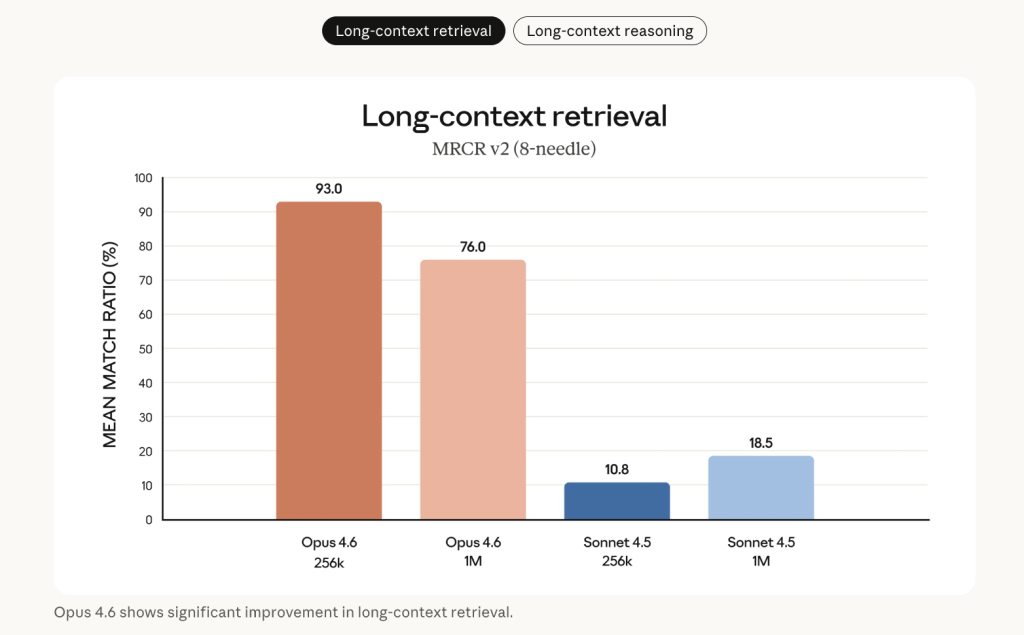
Long-context retrieval is a central improvement. On the 8-needle 1M variant of MRCR v2 — a ‘needle-in-a-haystack’ benchmark where facts are buried inside 1M tokens of text — Opus 4.6 scores 76%, compared to 18.5% for Claude Sonnet 4.5. Anthropic describes this as a qualitative shift in how much context a model can actually use without context rot.
Additional performance gains in:
root cause analysis on complex software failures
multilingual coding
long-term coherence and planning
cybersecurity tasks
life sciences, where Opus 4.6 performs almost 2× better than Opus 4.5 on computational biology, structural biology, organic chemistry, and phylogenetics evaluations
On Vending-Bench 2, a long-horizon economic performance benchmark, Opus 4.6 earns $3,050.53 more than Opus 4.5 under the reported setup.
Key Takeaways
Opus 4.6 is Anthropic’s highest-end model with 1M-token context (beta): Supports 1M input tokens and up to 128k output tokens, with premium pricing above 200k tokens, making it suitable for very long codebases, documents, and multi-step agentic workflows.
Explicit controls for reasoning depth and cost via effort and adaptive thinking: Developers can tune /effort (low, medium, high, max) and let ‘adaptive thinking’ decide when extended reasoning is needed, exposing a clear latency vs accuracy vs cost trade-off for different routes and tasks.
Strong benchmark performance on coding, search, and economic value tasks: Opus 4.6 leads on GDPval-AA, Terminal-Bench 2.0, Humanity’s Last Exam, BrowseComp, and MRCR v2 1M, with large gains over Claude Opus 4.5 and GPT-class baselines in long-context retrieval and tool-augmented reasoning.
Tight integration with Claude Code, Excel, and PowerPoint for real workloads: Agent teams in Claude Code, structured Excel transformations, and template-aware PowerPoint generation position Opus 4.6 as a backbone for practical engineering and analyst workflows, not just chat.
Check out the Technical details and Documentation. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
Max is an AI analyst at MarkTechPost, based in Silicon Valley, who actively shapes the future of technology. He teaches robotics at Brainvyne, combats spam with ComplyEmail, and leverages AI daily to translate complex tech advancements into clear, understandable insights
