
: Self-Improving LLMs via Evolving Contexts, Not")
TL;DR: A team of researchers from Stanford University, SambaNova Systems and UC Berkeley introduce ACE framework that improves LLM performance by editing and growing the input context instead of updating model weights. Context is treated as a living “playbook” maintained by three roles—Generator, Reflector, Curator—with small delta items merged incrementally to avoid brevity bias and context collapse. Reported gains: +10.6% on AppWorld agent tasks, +8.6% on finance reasoning, and ~86.9% average latency reduction vs strong context-adaptation baselines. On the AppWorld leaderboard snapshot (Sept 20, 2025), ReAct+ACE (59.4%) ≈ IBM CUGA (60.3%, GPT-4.1) while using DeepSeek-V3.1.
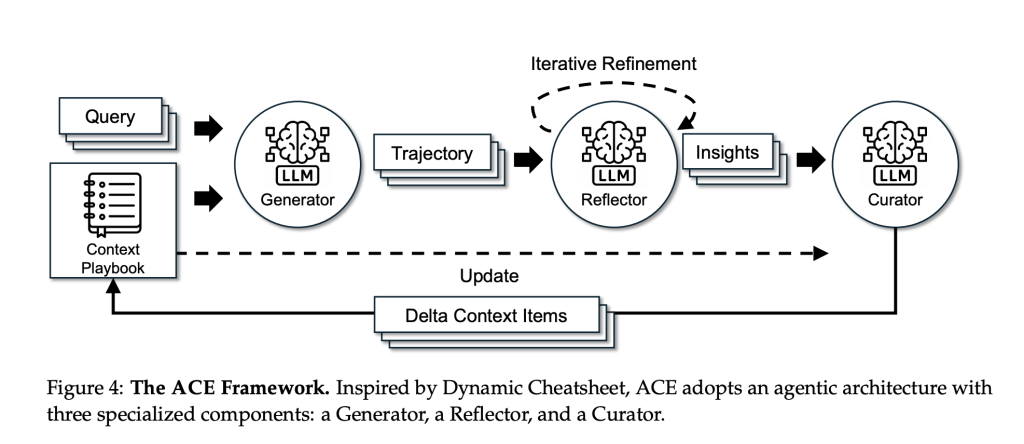
What ACE changes?
ACE positions “context engineering” as a first-class alternative to parameter updates. Instead of compressing instructions into short prompts, ACE accumulates and organizes domain-specific tactics over time, arguing that higher context density improves agentic tasks where tools, multi-turn state, and failure modes matter.
Method: Generator → Reflector → Curator
Generator executes tasks and produces trajectories (reasoning/tool calls), exposing helpful vs harmful moves.
Reflector distills concrete lessons from those traces.
Curator converts lessons into typed delta items (with helpful/harmful counters) and merges them deterministically, with de-duplication and pruning to keep the playbook targeted.
Two design choices—incremental delta updates and grow-and-refine—preserve useful history and prevent “context collapse” from monolithic rewrites. To isolate context effects, the research team fixes the same base LLM (non-thinking DeepSeek-V3.1) across all three roles.
Benchmarks
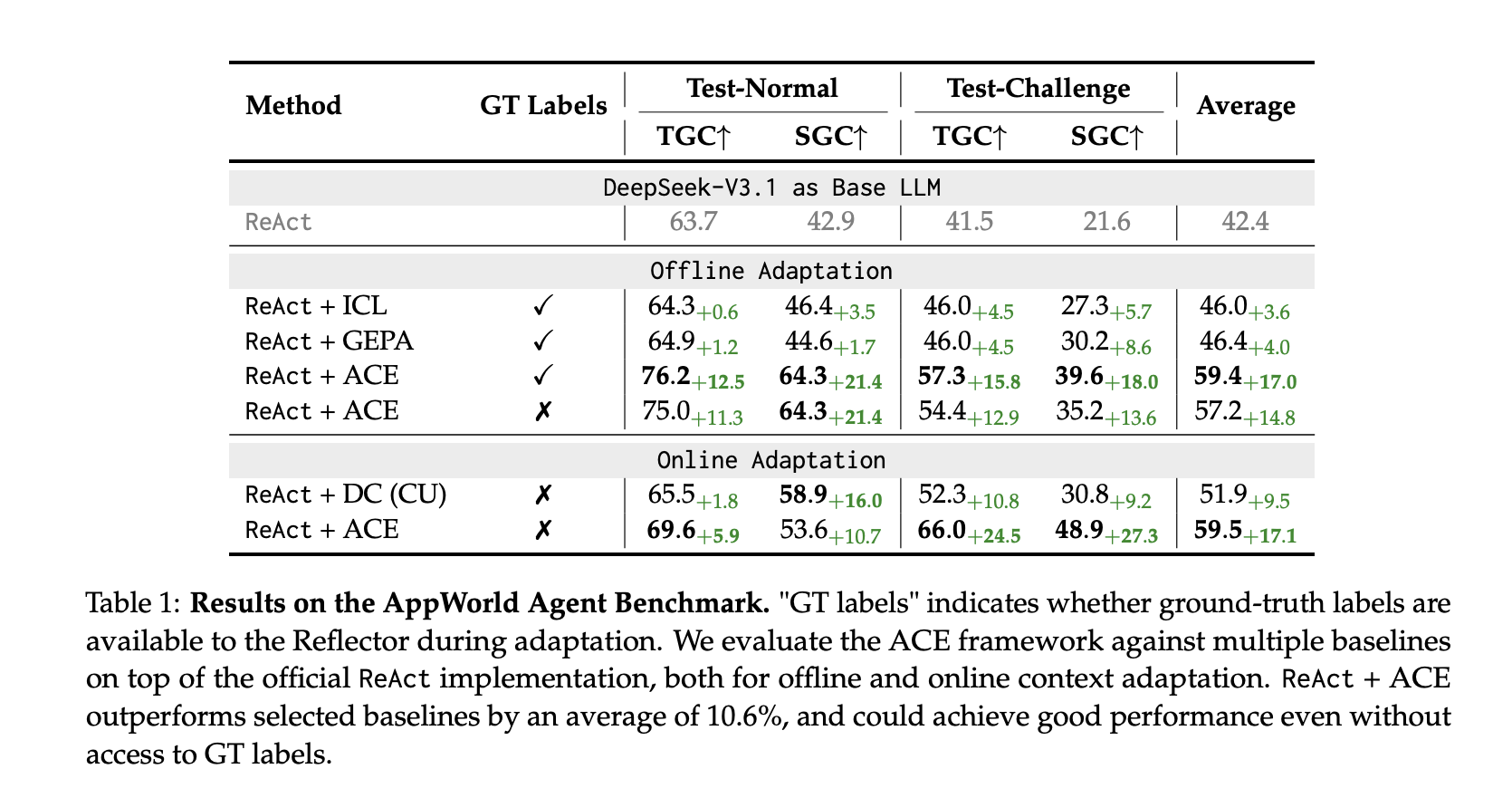
AppWorld (agents): Built on the official ReAct baseline, ReAct+ACE outperforms strong baselines (ICL, GEPA, Dynamic Cheatsheet), with +10.6% average over selected baselines and ~+7.6% over Dynamic Cheatsheet in online adaptation. On the Sept 20, 2025 leaderboard, ReAct+ACE 59.4% vs IBM CUGA 60.3% (GPT-4.1); ACE surpasses CUGA on the harder test-challenge split, while using a smaller open-source base model.
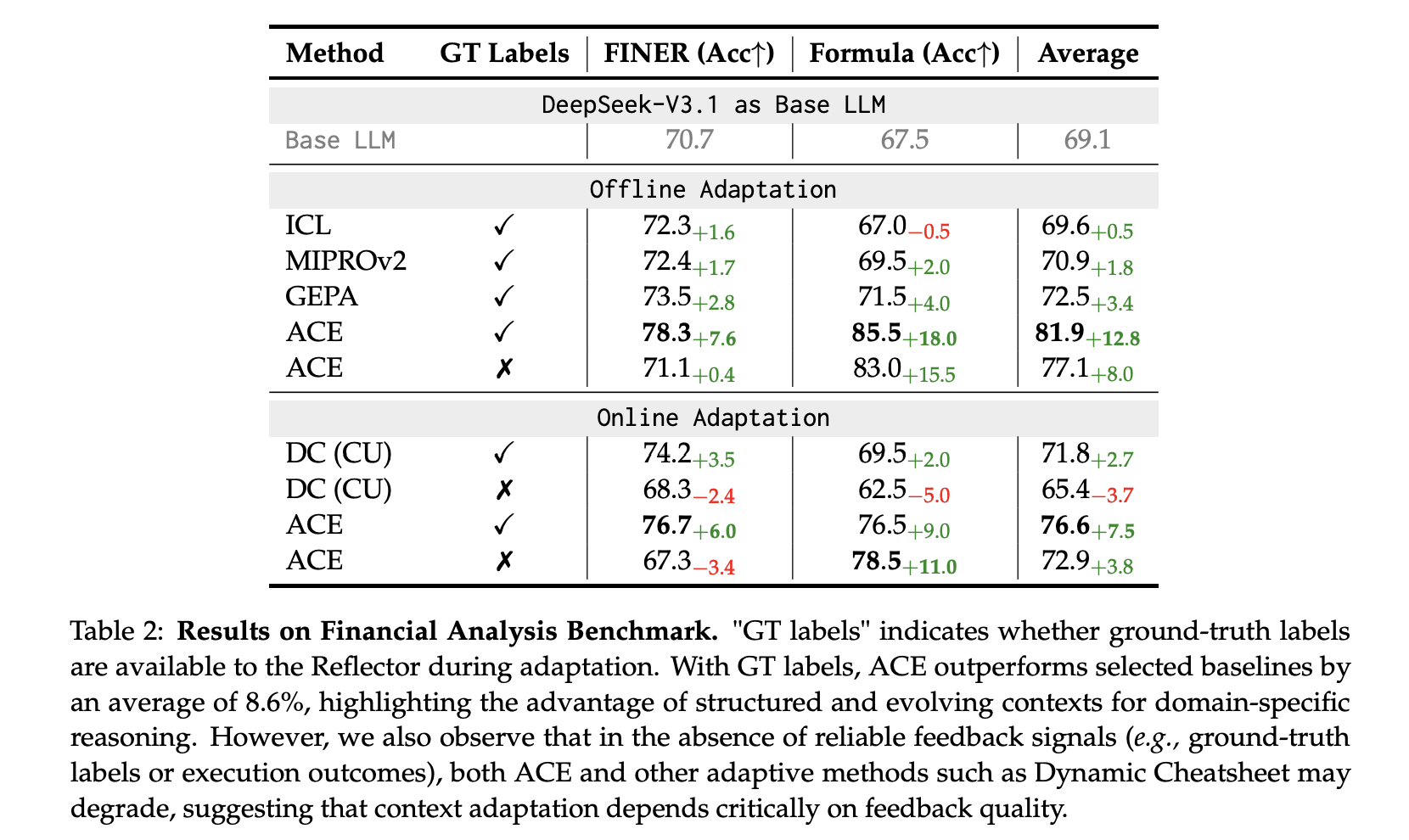
Finance (XBRL): On FiNER token tagging and XBRL Formula numerical reasoning, ACE reports +8.6% average over baselines with ground-truth labels for offline adaptation; it also works with execution-only feedback, though quality of signals matters.
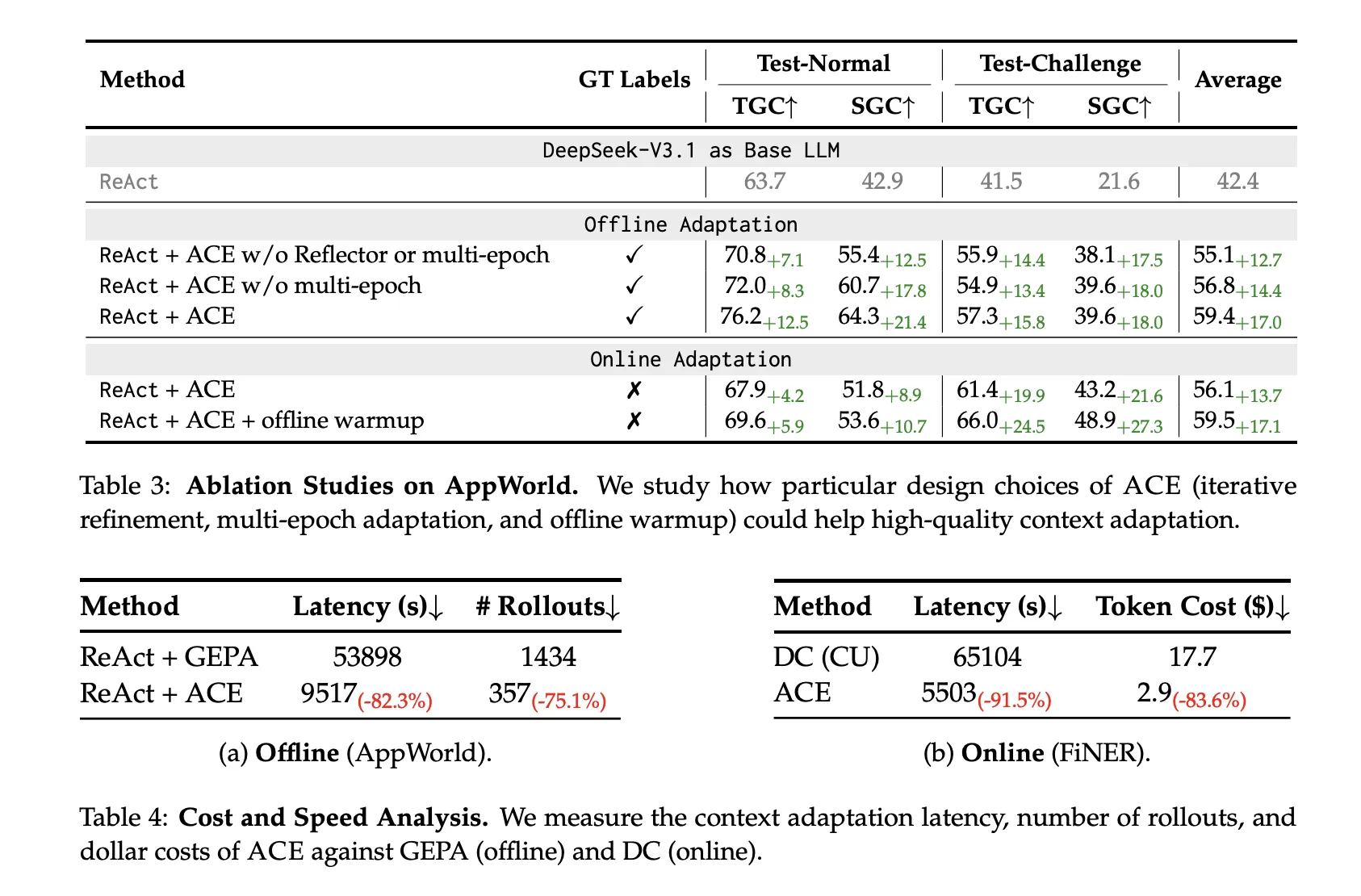
Cost and latency
ACE’s non-LLM merges plus localized updates reduce adaptation overhead substantially:
Offline (AppWorld): −82.3% latency and −75.1% rollouts vs GEPA.
Online (FiNER): −91.5% latency and −83.6% token cost vs Dynamic Cheatsheet.
Key Takeaways
ACE = context-first adaptation: Improves LLMs by incrementally editing an evolving “playbook” (delta items) curated by Generator→Reflector→Curator, using the same base LLM (non-thinking DeepSeek-V3.1) to isolate context effects and avoid collapse from monolithic rewrites.
Measured gains: ReAct+ACE reports +10.6% over strong baselines on AppWorld and achieves 59.4% vs IBM CUGA 60.3% (GPT-4.1) on the Sept 20, 2025 leaderboard snapshot; finance benchmarks (FiNER + XBRL Formula) show +8.6% average over baselines.
Lower overhead than reflective-rewrite baselines: ACE reduces adaptation latency by ~82–92% and rollouts/token cost by ~75–84%, contrasting with Dynamic Cheatsheet’s persistent memory and GEPA’s Pareto prompt evolution approaches.
Conclusion
ACE positions context engineering as a first-class alternative to weight updates: maintain a persistent, curated playbook that accumulates task-specific tactics, yielding measurable gains on AppWorld and finance reasoning while cutting adaptation latency and token rollouts versus reflective-rewrite baselines. The approach is practical—deterministic merges, delta items, and long-context–aware serving—and its limits are clear: outcomes track feedback quality and task complexity. If adopted, agent stacks may “self-tune” primarily through evolving context rather than new checkpoints.
Check out the PAPER here. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.