
: A Step Wise")

How can a small model learn to solve tasks it currently fails at, without rote imitation or relying on a correct rollout? A team of researchers from Google Cloud AI Research and UCLA have released a training framework, ‘Supervised Reinforcement Learning’ (SRL), that makes 7B scale models actually learn from very hard math and agent trajectories that normal supervised fine tuning and outcome based reinforcement learning RL cannot learn from.
Small open source models such as Qwen2.5 7B Instruct fail on the hardest problems in s1K 1.1, even when the teacher trace is good. If we apply supervised fine tuning on the full DeepSeek R1 style solutions, the model imitates token by token, the sequence is long, the data is only 1,000 items, and the final scores drop below the base model.
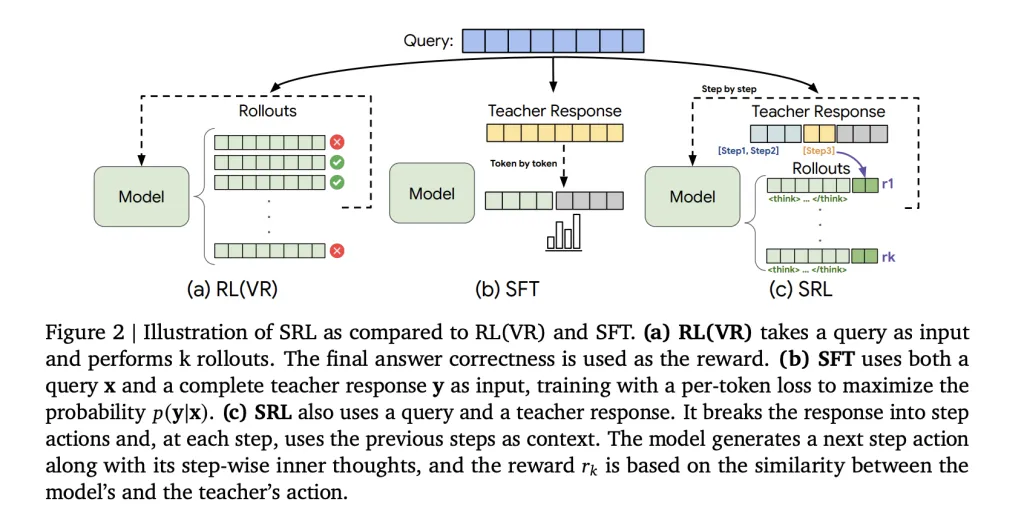
Core idea of ‘Supervised Reinforcement Learning’ SRL
‘Supervised Reinforcement Learning’ (SRL) keeps the RL style optimization, but it injects supervision into the reward channel instead of into the loss. Each expert trajectory from s1K 1.1 is parsed into a sequence of actions. For every prefix of that sequence, the research team creates a new training example, the model first produces a private reasoning span wrapped in <think> … </think>, then it outputs the action for that step, and only this action is compared with the teacher action using a sequence similarity metric based on difflib. The reward is dense because every step has a score, even when the final answer is wrong. The rest of the text, the reasoning part, is not constrained, so the model can search its own chain without being forced to copy the teacher tokens.
Math results
All models are initialized from Qwen2.5 7B Instruct and all are trained on the same DeepSeek R1 formatted s1K 1.1 set, so comparisons are clean. The exact numbers in Table 1 are:
Base Qwen2.5 7B Instruct, AMC23 greedy 50.0, AIME24 greedy 13.3, AIME25 greedy 6.7.
SRL, AMC23 greedy 50.0, AIME24 greedy 16.7, AIME25 greedy 13.3.
SRL then RLVR, AMC23 greedy 57.5, AIME24 greedy 20.0, AIME25 greedy 10.0.
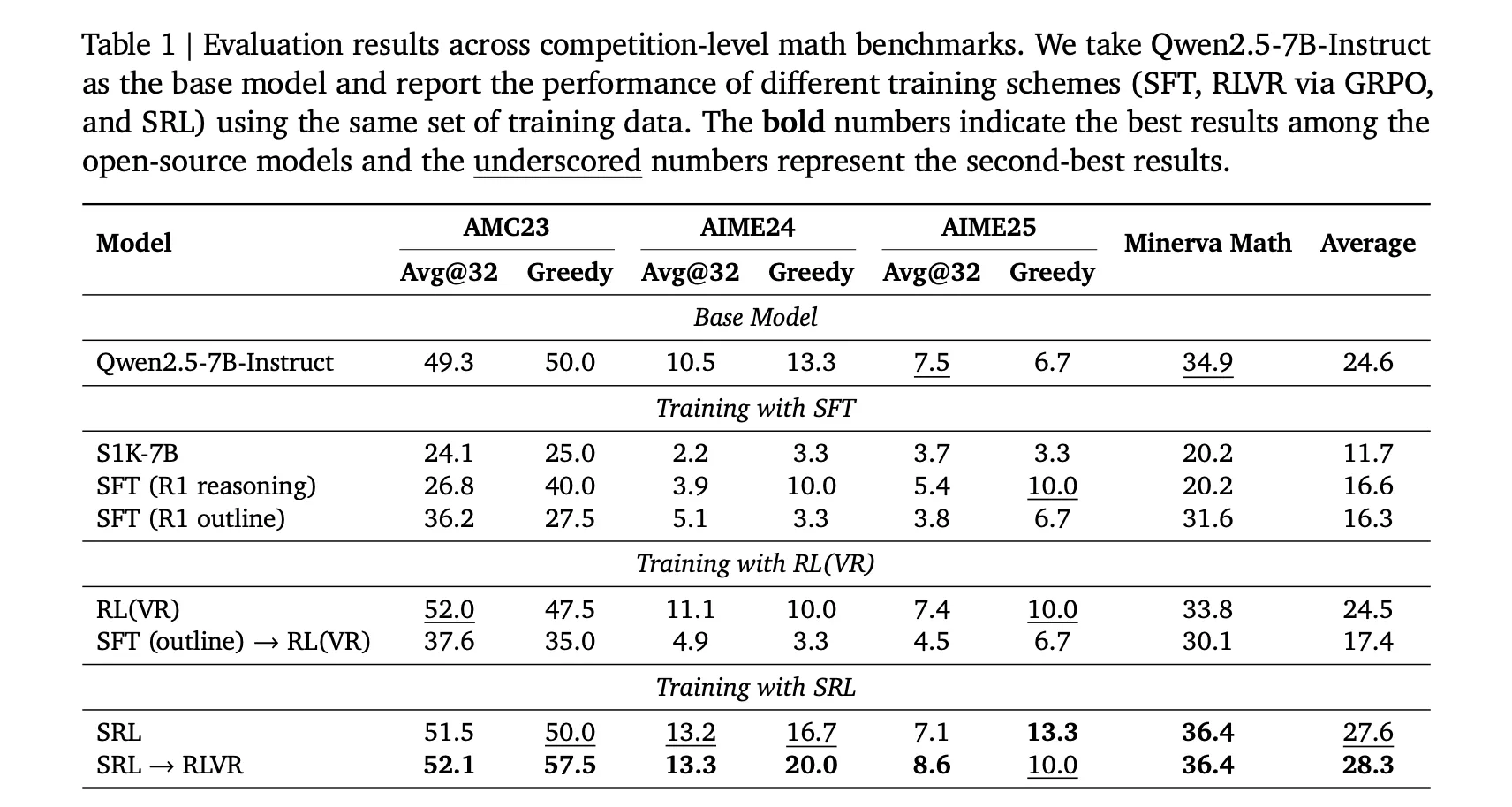
This is the key improvement, SRL alone already removes the SFT degradation and raises AIME24 and AIME25, and when RLVR is run after SRL, the system reaches the best open source scores in the research. The research team is explicit that the best pipeline is SRL then RLVR, not SRL in isolation.
Software engineering results
The research team also applies SRL to Qwen2.5 Coder 7B Instruct using 5,000 verified agent trajectories generated by claude 3 7 sonnet, every trajectory is decomposed into step wise instances, and in total 134,000 step items are produced. Evaluation is on SWE Bench Verified. The base model gets 5.8 percent in the oracle file edit mode and 3.2 percent end to end. SWE Gym 7B gets 8.4 percent and 4.2 percent. SRL gets 14.8 percent and 8.6 percent, which is about 2 times the base model and clearly higher than the SFT baseline.
Key Takeaways
SRL reformulates hard reasoning as step wise action generation, the model first produces an internal monologue then outputs a single action, and only that action is rewarded by sequence similarity, so the model gets signal even when the final answer is wrong.
SRL is run on the same DeepSeek R1 formatted s1K 1.1 data as SFT and RLVR, but unlike SFT it does not overfit long demonstrations, and unlike RLVR it does not collapse when no rollout is correct.
On math, the exact order that gives the strongest results in the research is, initialize Qwen2.5 7B Instruct with SRL, then apply RLVR, which pushes reasoning benchmarks higher than either method alone.
The same SRL recipe generalizes to agentic software engineering, using 5,000 verified trajectories from claude 3 7 sonnet 20250219, and it lifts SWE Bench Verified well above both the base Qwen2.5 Coder 7B Instruct and the SFT style SWE Gym 7B baseline.
Compared to other step wise RL methods that need an extra reward model, this SRL keeps a GRPO style objective and uses only actions from expert trajectories and a lightweight string similarity, so it is easy to run on small hard datasets.
‘Supervised Reinforcement Learning’ (SRL) is a practical contribution by the research team. It keeps the GRPO style reinforcement learning setup, but it replaces fragile outcome level rewards with supervised, step wise rewards that are computed directly from expert trajectories, so the model always receives informative signal, even in the Dhard regime where RLVR and SFT both stall. It is important that the research team shows SRL on math and on SWE Bench Verified with the same recipe, and that the strongest configuration is SRL followed by RLVR, not either one alone. This makes SRL a realistic path for open models to learn hard tasks. Overall, SRL is a clean bridge between process supervision and RL that open model teams can adopt immediately.
Check out the Paper. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.