

Robots are entering their GPT-3 era. For years, researchers have tried to train robots using the same autoregressive (AR) models that power large language models (LLMs). If a model can predict the next word in a sentence, it should be able to predict the next move for a robotic arm. However, a technical wall has blocked this progress: continuous robot movements are difficult to turn into discrete tokens.
A team of researchers from Harvard University and Stanford University have released a new framework called Ordered Action Tokenization (OAT) to bridge this gap.
The Messy Reality of Robot Actions
Tokenization turns complex data into a sequence of discrete numbers (tokens). For robots, these actions are continuous signals like joint angles. Previous strategies had fatal flaws:
Binning: Turns every action dimension into a ‘bin.’ While simple, it creates massive sequences that make training and inference slow.
FAST (Frequency-space Action Sequence Tokenization): Uses math to compress movements into frequency coefficients. It is fast but often produces ‘undecodable’ sequences where small errors cause the robot to halt or move unpredictably.
Learned Latent Tokenizers: These use a learned ‘dictionary’ of movements. They are safe but lack a specific order, meaning the model treats early and late tokens as equally important.

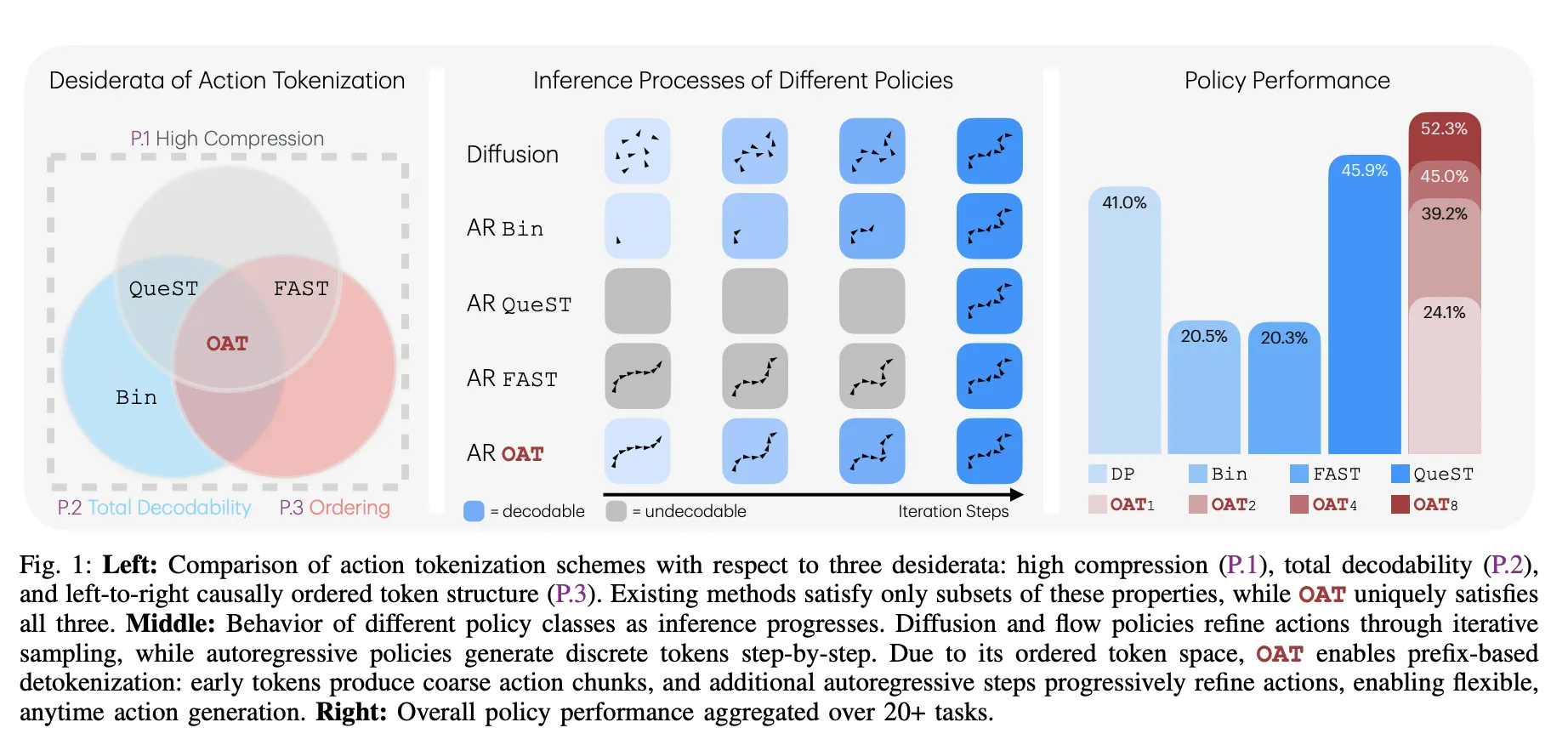
The Three Golden Rules of OAT
The research team identified 3 essential properties—desiderata—for a functional robot tokenizer:
High Compression (P.1): Token sequences must be short to keep models efficient.
Total Decodability (P.2): The decoder must be a total function, ensuring every possible token sequence maps to a valid movement.
Causal Ordering (P.3): Tokens must have a left-to-right structure where early tokens capture global motion and later tokens refine details.
The Secret Sauce: Nested Dropout and Registers
OAT uses a transformer encoder with register tokens to summarize action chunks. To force the model to learn ‘important’ things first, the research team used a innovative approach called Nested Dropout.

Breaking the Benchmarks
The research team tested OAT across 20+ tasks in 4 major simulation benchmarks. OAT consistently outperformed the industry-standard Diffusion Policy (DP) and previous tokenizers.
Performance Results
‘Anytime’ Inference: Speed vs. Precision
The most practical benefit of OAT is prefix-based detokenization. Since the tokens are ordered by importance, you can stop the model early.
Coarse Actions: Decoding just 1 or 2 tokens gives the robot a general direction quickly, which is useful for low-latency tasks.
Fine Actions: Generating all 8 tokens provides the high-precision details needed for complex insertions.
This allows for a smooth trade-off between computation cost and action fidelity that previous fixed-length tokenizers could not offer.
Key Takeaways
Solving the Tokenization Gap: OAT addresses a fundamental limitation in applying autoregressive models to robotics by introducing a learned tokenizer that simultaneously achieves high compression, total decodability, and causal ordering.
Ordered Representation via Nested Dropout: By utilizing nested dropout during training, OAT forces the model to prioritize global, coarse motion patterns in early tokens while reserving later tokens for fine-grained refinements.
Total Decodability and Reliability: Unlike prior frequency-domain methods like FAST, OAT ensures the detokenizer is a total function, meaning every possible token sequence generates a valid action chunk, preventing runtime execution failures.
Flexible ‘Anytime’ Inference: The ordered structure enables prefix-based decoding, allowing robots to execute coarse actions from just one or two tokens to save computation or full eight-token sequences for high-precision tasks.
Superior Performance Across Benchmarks: Autoregressive policies equipped with OAT consistently outperform diffusion-based baselines and other tokenization schemes, achieving a 52.3% aggregate success rate and superior results in real-world ‘Pick & Place’ and ‘Stack Cups’ tasks.
Check out the Paper, Repo and Project Page. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.

Michal Sutter is a data science professional with a Master of Science in Data Science from the University of Padova. With a solid foundation in statistical analysis, machine learning, and data engineering, Michal excels at transforming complex datasets into actionable insights.
