
AI News
LLMs Can Now Learn to Try Again: Researchers from Menlo Introduce ReZero, a Reinforcement Learning Framework That Rewards Query Retrying to Improve Search-Based Reasoning in RAG Systems
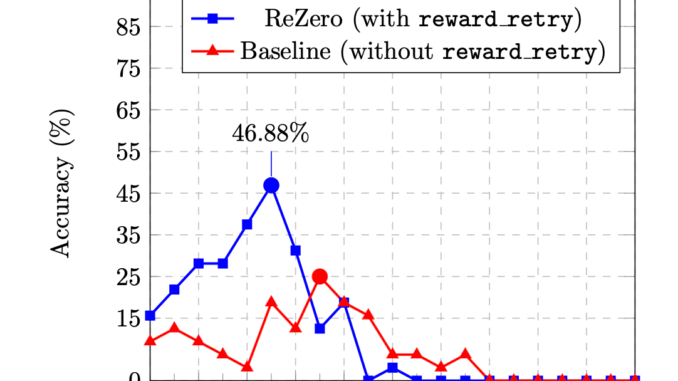
The domain of LLMs has rapidly evolved to include tools that empower these models to integrate external knowledge into their reasoning processes. A significant advancement in this direction is Retrieval-Augmented Generation (RAG), which allows models […]








